目次
AWSの「Amazon Titan」を徹底解説:何が強みで、どこで使うべきか(2025年最新版)
はじめに
みなさん、今日は AWS が自社で事前学習した生成 AI ファミリー「Amazon Titan」(以下、Titan)を取り上げます。Bedrock 上で提供される Titan は、テキスト生成・画像生成・埋め込み(ベクトル化)などの用途に対応し、企業の実運用に耐えるセキュリティやガバナンス機能と深く結び付いているのが特徴です。まず全体像を押さえ、歴史と最新アップデート、そして競合モデルとの比較、最後に「使いどころ(導入判断の軸)」まで、授業形式で丁寧に整理していきます。
1. Titanの全体像(ラインナップと基本機能)
みなさん、最初にどんなモデルがあるのか把握しましょう。2025年時点で AWS 公式が案内する Titan の主な系統は次のとおりです。
- Titan Text(テキスト生成):軽量の Text G1-Lite から、より高性能な Express/Premier 系まで。用途は要約、Q&A、抽出、変換、思考の連鎖など。最大トークン数や対応言語、推論パラメータはモデルごとに異なります。
- Titan Text Embeddings V2(埋め込み):最大 8,192 トークン(約 50,000 文字)を入力でき、1,024 次元のベクトル出力に対応。RAG(検索拡張生成)やレコメンドの土台に適します。
- Titan Multimodal Embeddings G1:テキスト+画像などの多モーダル埋め込み。
- Titan Image Generator G1(画像生成):v1 と v2 を提供。テキスト→画像、インペインティング/アウトペインティング、バリエーション生成、v2 ではカラーパレット制御・背景自動削除・条件付き生成(Canny/Segmentation)などの拡張を備えます。
ここでのポイントは、Bedrock の標準 API と周辺機能(ガードレール、ナレッジベース、Flows など)と密に統合されていることです。これにより、企業はセキュリティ・プライバシー・運用面を含めて “クラウドネイティブ” にモデルを扱えます。
例え話:
Titan は「AWS データセンターという安全なキャンパスの中にある研究室」で、となりの建物(S3、Lambda、RDS、IAM など)と渡り廊下でつながっているイメージです。廊下(Bedrock の API や Flows)を通じて模型(モデル)と資料(データ)を安全にやり取りできるから、設計から製造、検査までが同じ敷地で完結しやすいのです。
2. 歴史と最新の状況(2025年時点)
- 出自:Titan は AWS が自社で事前学習した基盤モデル群として 2023 年から段階的に公開され、Bedrock の柱の一つになりました。以降、Text/Embeddings/Image 系が順次拡充されています。
- 2024〜2025 の注目アップデート(画像生成):
- Titan Image Generator は不可視ウォーターマークを標準付与し、Bedrock コンソールや API で検出できます(プレビュー、対象リージョンは us-east-1 / us-west-2)。v2 では条件付き生成や背景除去など実務に効く機能が強化。
- 2025年3月にはウォーターマーク検出の堅牢性を改善したアップデートが告知されています(研究者報告への対応として AWS が改善を公表)。
- プラットフォーム面:Bedrock では オンデマンド/バッチ/プロビジョンドスループットといった柔軟な課金・提供形態、Flows(ノーコードに近いワークフロー作成)、Guardrails(有害コンテンツや PII 対策、幻覚低減のための基盤機能)などが拡充されています。Flows は 1,000 ノード遷移あたり 0.035 USD(2025/2/1〜)と明確化されています。
3. Titanの強み(AWS視点での“実務適性”)
みなさん、ここが Titan を選ぶかどうかの肝です。
1) セキュリティ&ガバナンスの一体運用 Bedrock の Guardrails はトキシックなテキスト・画像の検出/ブロック、禁止トピック、ワードフィルタ、PII マスキング、根拠付け(Grounding)や自動推論チェックまでカバー。プロンプトと応答の両方に適用でき、複数モデルへ一貫したポリシー配備が可能です。
2) 責任ある AI(コンテンツ出所の証跡) Titan Image は不可視ウォーターマークと C2PA メタデータを付与。Bedrock の検出機能(プレビュー)や外部の Content Credentials Verify で確認できます。フェイク検知・著作権管理・ブランド保護の設計が明確です。
3) 埋め込み(Embeddings)の実用度 8,192 トークン入力・1,024 次元の Embeddings V2 は、長文の意味検索やクラスタリングに有効。運用では段落単位の分割が推奨されています。
4) 画像生成の実務機能 v2 の背景自動削除・色制御・条件付き生成、最大 4,096×4,096(バリエーション時) といった仕様は、EC/広告などブランド一貫性を求める現場で効きます。
5) 提供形態の柔軟さ(コスト最適化) オンデマンドで初期投資最小化、バッチで一括処理を安価に、プロビジョンドスループットで性能確保と割安化。Flows の従量や画像生成のサイズ別課金など、費用見通しを立てやすいのも運用面で利点です。
例え話:
ガードレールやウォーターマークは「工場の品質検査工程」に相当します。製品(生成物)の品質をロット単位で担保し、あとでトレーサビリティ(出所の追跡)もできる。安全規格に適合した生産ラインを最初から選ぶことが、監査対応やブランドリスク抑制につながります。
4. 競合モデルとの比較(Claude / OpenAI / Cohere ほか)
みなさん、Titan を「いつ使うか」は他モデルとの補完関係で考えるのが現実的です。Bedrock では Anthropic Claude、Meta Llama、Mistral なども選べます。
- 長文推論・高度な会話設計:企業チャットやコーディング支援でClaude 系は強力(近年は超大規模コンテキスト化の動き)。ただしポリシー適用やガバナンスは Bedrock 機能(Guardrails 等)で一元化できます。
- 汎用生成の SOTA 競争:OpenAI/Gemini などの“トップティア”とも競合しますが、Titan は「AWS ネイティブ&責任ある AI」設計が明確で、埋め込み・画像の“運用要件”で光る場面が多いです。
- Embeddings の比較観点:Titan V2 はノイズ耐性や文レベル意味保持の評価報告もあり、ドキュメント検索や FAQ 自動応答の基盤として十分に戦えます。
まとめると、推論最強の 1 強を決めるより、用途×運用制約で選び分ける発想が重要です。Titan は「AWS のセキュアな土台上で、責任ある生成を標準化」する文脈でベストチョイスになりやすいのです。
5. 具体的な使いどころ(導入判断の軸)
ここからは「みなさんの現場」に落とし込みます。
5-1. Titan が第一候補になるケース
- コンプライアンス重視の生成ワークフロー
- 例:コールセンター要約で PII マスキング、ナレッジ生成で 幻覚低減(Grounding)、禁止トピックの管理を一貫して設定したい。→ Guardrails と Titanの組み合わせは設計が簡潔。
- 画像生成で“ブランド一貫性”と“来歴管理”が必須
- 例:EC 商品画像の量産・背景除去・色指定・不可視ウォーターマーク付与。社内で生成物の出所確認も行いたい。→ Titan Image v2 + 検出 API が合致。
- 大規模 RAG のベース埋め込み
- 長文を8,192 トークンまで受けられ、1,024 次元で検索精度を確保。→ 文書系システムの下支えに Titan Embeddings V2。
- AWS サービスと一気通貫の運用
- S3・IAM・CloudWatch・KMS・VPC などと共存しやすいのが Titan/Bedrock。Flows の料金体系(0.035 USD/1,000 遷移)も明瞭で、社内稟議が通しやすい。
5-2. 他モデルを主役にする方がよいケース
- 英語の超高難度推論・大規模コンテキストが最優先
- たとえば超長文のリーガル推論や1M トークン級の会話保持を最重視するなら、Claude の最新大窓などを検討(ただしコスト・レイテンシは要評価)。
- 特定ベンチマークでの SOTA を追求
- 研究用途で「このベンチでトップ」という要件が堅いなら、SOTA 競合(OpenAI/Gemini など)を試験導入し、Guardrails を併用してガバナンスは Bedrock 側で担保。
6. 仕様と数値で見る Titan(“運用で効く”ディテール集)
- Embeddings(V2):入力 最大 8,192 トークン / 50,000 文字、出力 1,024 次元。長文 RAG のベースに向く。
- Image v1/v2:
- 入力プロンプト 最大 512 文字、入力画像 最大 5MB、編集系は長辺 ≤1,408px、バリエーションは 最大 4,096×4,096。
- v2 限定機能:色パレット制御(HEX 1〜10色)、背景自動削除、条件付き生成(Canny/Segmentation)、被写体一貫性。
- 不可視ウォーターマーク+C2PA 付与、検出はプレビュー(us-east-1/us-west-2)。
- Guardrails:有害コンテンツのカテゴリ別しきい値、禁止トピック、ワードフィルタ、PII マスキング、Grounding/自動推論チェックなど。プロンプト/応答の両面に適用可能。
- 料金・提供形態:オンデマンド/バッチ(オンデの50%オフ対象モデルあり)/プロビジョンド。Flows:0.035 USD/1,000 遷移。サイズ別課金(画像)など、見積根拠を作りやすい。
7. 使い方の流れ(導入パターン別の“型”)
A. RAG/社内検索(ドキュメント QA)
- S3 等に文書格納 → Bedrock Knowledge Bases で取り込み
- Embeddings V2(8,192 トークン / 1,024 次元)で索引化
- Titan Text(Lite/Express/Premier のいずれか)で回答生成
- Guardrails で PII・有害表現・根拠チェックを設定
→ 「低幻覚・監査対応の社内 QA」が短期間に構築可能。
B. 画像生成のブランド運用
- v2 の色パレット・被写体一貫性でブランドガイドに沿った生成
- 背景自動削除で商品切り抜き、不可視ウォーターマークで来歴管理
- 必要に応じてバリエーション(〜4K)を回し、A/B テスト
→ EC・広告・SNS で大量・一貫・検証可能な生成ラインを実現。
C. ガードレール先行の社内移行
- 既存の生成アプリに ApplyGuardrail API を適用
- 徐々に推論エンジンを Titan/他モデルに切り替え
→ 安全基盤を先に標準化し、モデルは“差し替え可能”に。
8. Titan を選ぶかの最終チェックリスト
みなさん、最後は意思決定のフレームです。次の質問に Yes が多ければ Titan 優位です。
- AWS ネイティブ運用(IAM/VPC/KMS/CloudWatch/S3 連携)を前提としているか?
- コンテンツの出所管理や監査対応(ウォーターマーク/C2PA)が必要か?
- PII や有害表現、幻覚対策を構成要素として標準化したいか?(Guardrails)
- 長文 RAG 向けの安定した埋め込み(8192 トークン/1024 次元)が重要か?
- 費用対効果と提供形態(オンデ・バッチ・PT)の柔軟性を重視するか?(Flows の従量含む)
9. まとめ
- Titan は 「AWS ネイティブな責任ある生成 AI」を掲げ、Guardrails・ウォーターマーク・C2PA 等でエンタープライズの安全基盤を先に整備したファミリーです。
- Embeddings V2(8192t/1024d)・Image v2(背景除去・色制御・条件付き生成・4K バリエーション)など、運用要件に刺さる仕様が多く、RAG・EC・広告に相性が良い。
- 競合が強い長文推論や SOTA 競争領域でも、Bedrock 側のガバナンスを共通化すれば共存・併用が容易。実務では「用途×制約でモデルを選び、安全と運用を先に固める」発想が成果に直結します。
付録:Titanを他モデルと選び分ける早見表(要点)
- Titan:AWS ネイティブ、責任ある生成、画像の来歴管理、RAG 基盤の安定性
- Claude:大窓・会話・コーディングの総合力(ただし要費用試算)
- OpenAI/Gemini:SOTA 競争の筆頭、特定ベンチで優位
- Cohere/Meta/Mistral:コストやホスティング選択肢、用途特化で補完
(上記は Bedrock 上でGuardrails を共通適用しながら併用する発想が現実的)

NEW BOOK 2026/06/01
Brain to Product
声で意図を渡し、プロダクトをつくる。
ぽちょ研究所代表・平野素大の新刊。音声入力とAIエージェントで、頭の中の違和感や意図を実装へ渡す開発論です。
Amazonで覗いてみる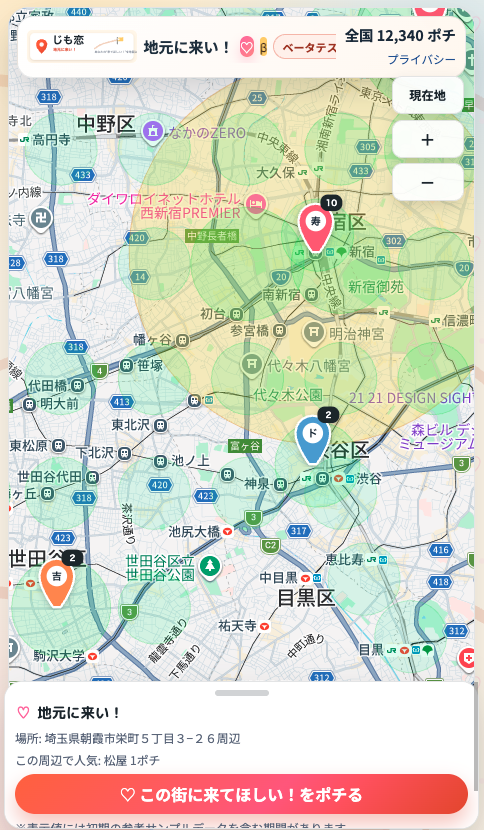
β TEST 2026/05/04
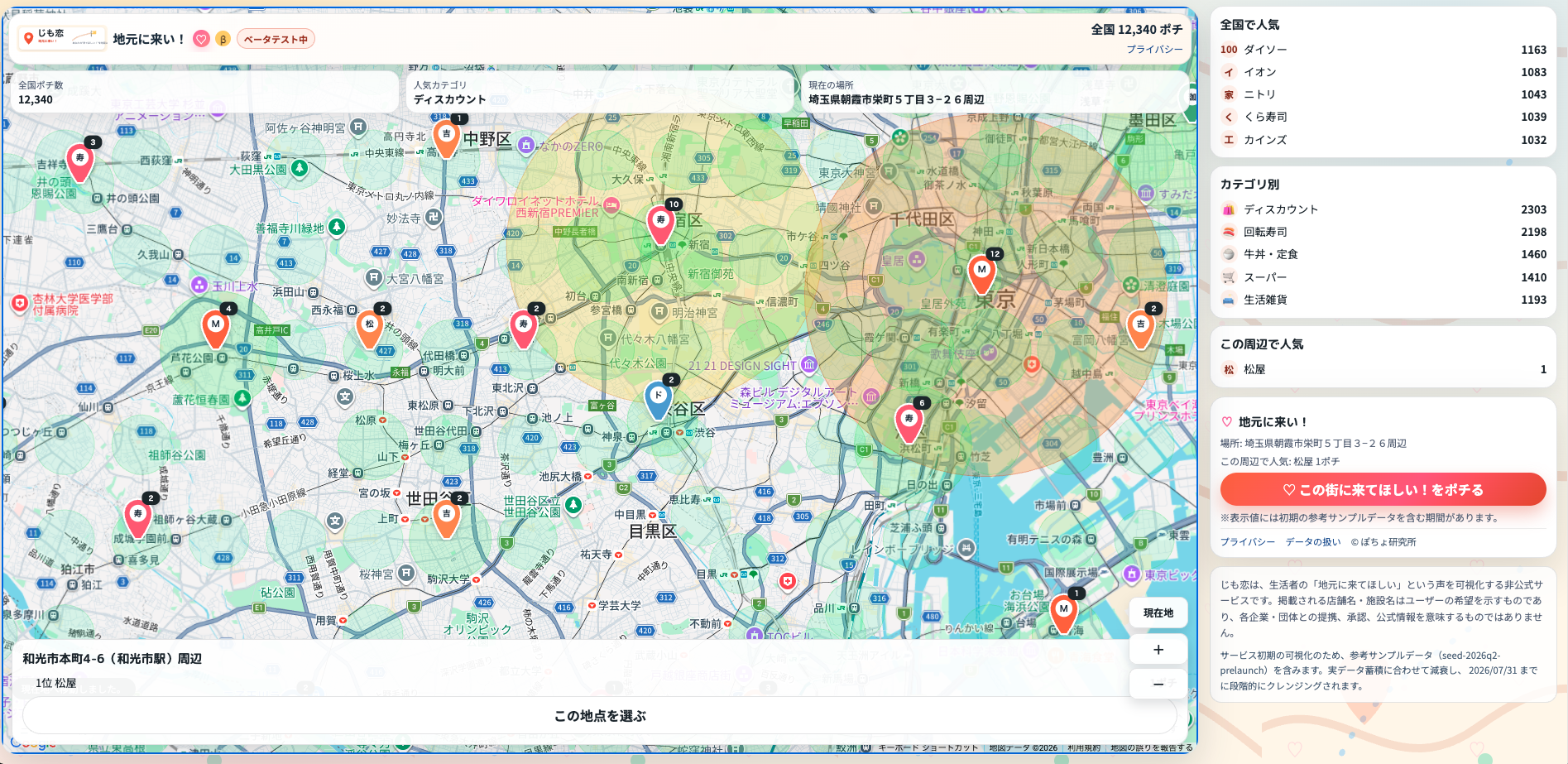
じも恋「地元に来い!」
あなたのポチるで、街の「足りない」を可視化。
住民のポチるを集め、地域ニーズをデータとして蓄積。誘致の保証はなくても、街の声を次の一手へつなげます。
ポチる
自叙伝ドットコム
あなたの人生は書く価値がある。
AIにだから語れる、本当の自分がある。記憶の断片を拾い集め、ひとつの物語へ。
覗いてみる関連記事
GPT-5.2とは?新機能・性能・価格を徹底解説
OpenAIが2025年12月11日に公開したGPT-5.2の全貌を解説。Instant・Thinking・Proの3モード、GPT-5.1からの進化点、API価格、競合との比較まで網羅的に紹介します。
AIはなぜ日本語が苦手なのか?構造的障壁と「英語中心」の壁、そして「完璧な翻訳」が訪れる未来
AIが日本語を苦手とする理由を、言語学的な構造的複雑さと英語中心の学習データという2つの壁から解説。誤読や誤認識の原因、そして完璧な日本語AIが現れる未来を予測します。
新たなコーディングフロンティア:CursorのComposerとエージェント速度の時代
2025年10月に発表されたCursor Composer 1とCursor 2.0は、AIコーディング支援の新時代を切り開きます。開発者の「フロー状態」を守る高速モデルと、マルチエージェントワークフローの徹底解説。
RAG(検索拡張生成)とは?生成AI・AIエージェント・MCPとの違いを完全解説
注目のAI技術「RAG(検索拡張生成)」を初心者向けに徹底解説。生成AI、AIエージェント、MCPとの違いや関連性、ChatGPTのウェブ検索との関係まで分かりやすく紹介します。

AIにも国境が引かれた日|「知能」は輸出管理されるのか
Claude Fable 5とClaude Mythos 5の停止を起点に、AIモデルの重み、輸出管理、サイバー防衛、技術主権、そして「危険な知恵」を誰が管理するのかを考える長編考察です。