目次
全文検索エンジンとマネージドサービスの最新ベストプラクティス比較(2025年秋)
2025年秋時点の全文検索エンジンとマルチテナント検索のベストプラクティスについて、実践的な観点から詳しく解説いたします。
🔍 全文検索エンジンの現状
全文検索エンジンの代表例として、ElasticsearchやそのフォークであるOpenSearch(AWSや他社が提供するマネージドサービス)があります。いずれもApache Luceneベースの分散検索エンジンで、全文検索や分析、ベクトル検索など高度な機能を提供します。
💡 ライセンスの違い
Elasticsearchの商用版では一部機能が有料ですが、OpenSearchはApache 2.0ライセンスの下でフリーかつ活発に開発されており、コミュニティが成長しています。
全文検索は企業システムやウェブサービスで、少ない文字列や曖昧な検索でも関連情報を高速に返すために用いられます。ユーザーや組織ごとに見せたくないデータを隠す必要がある場合は、インデックス設計やアクセス制御が重要です。
以下では、マルチテナント環境での全文検索構築における主要ポイント(データ分割・アイソレーション、性能、コスト、運用性)を詳述いたします。
🏗️ マルチテナント検索のデータモデルと分割方式
マルチテナント検索では、複数テナントのデータをどのように分離・共有するかが鍵となります。AWSの設計ガイドなどでは、一般的にサイロモデル(隔離モデル)とプールモデル(共有モデル)の2方式が紹介されています。
サイロモデル(隔離モデル)
サイロモデルではテナントごとに独立したインデックス(またはクラスタ/ドメイン)を用意し、データを完全に分離します。
- 強固なアイソレーション:テナント間のデータ漏洩リスクが最小
- 個別最適化:テナント毎にスキーマやチューニングを最適化可能
- セキュリティ:IAMやリソースポリシーでインデックス毎にテナントを制限
✅ メリット:
- インデックス数やシャード数が多くなると、マスターの負荷やリソース管理が複雑
- AWSではドメイン内のシャード総数を3万未満(ノード当たり1000未満)に抑えることを推奨
- 数百~数千テナント規模では専用モデルの管理が困難になる場合があります
⚠️ 注意点:
🔧 大規模環境での対策: 多数テナント時は領域分割クラスタやテナント-インデックス対応データベースを併用するハイブリッド方式が提案されています。
プールモデル(共有モデル)
プールモデルでは全テナントのデータを1つ(あるいは少数)の共有インデックスに格納し、ドキュメント内のテナントIDフィールドで所属を識別します。
- 管理負荷の低減:すべてのデータを共有インデックスに格納
- コスト効率:リソースの共有により運用コストを削減
✅ メリット:
- データ混在による「ノイズテナント問題」が発生しやすい
- パフォーマンス劣化やアイソレーションに注意が必要
- 大規模(数万テナント)環境では、複数クラスタに分散配置し、テナントIDとインデックス対応を管理するDBで動的にルーティングする運用が推奨
⚠️ 注意点:
🔒 アイソレーションとアクセス制御
テナント間で情報漏洩が起きないよう、厳密なアクセス制御が不可欠です。
サイロモデルでのアクセス制御
サイロモデルではIAMやリソースポリシーでインデックス毎にテナントを制限できます。各テナントが専用のインデックスにアクセスするため、物理的な分離により高いセキュリティを実現できます。
プールモデルでのアクセス制御
プールモデルではドキュメントレベルで制御する必要があり、細粒度アクセス制御(FGAC)が重要です。
- ロールにインデックス単位やドキュメント/フィールド単位の権限を割り当て可能
- 各ユーザーが特定テナントIDを持つドキュメントだけを検索できるように設定
- ロールにテナントIDでフィルタする条件を設定すれば、各テナントは自分のデータのみを参照し、他テナントの結果は除外
🔧 OpenSearchのFGAC機能:
💡 重要な違い
OpenSearchはRBACやドキュメント/フィールドレベルセキュリティを無償で提供しており、Elastic OSS版では有料となるこれら機能が最初から利用可能です。
⚡ パフォーマンスとスケーラビリティ
検索性能を高めるにはクラスタ構成やインデックス設計が重要です。
シャーディングとレプリケーション
OpenSearch/Elasticsearchではシャーディングとレプリケーションで水平スケールでき、各シャードのサイズは10~50GB程度が推奨されています。
- インバーテッドインデックス+BM25で実行
- ほぼリアルタイムに近い応答が可能
- デフォルトのインデックス更新間隔(refresh_interval)は1秒に設定
- 新着ドキュメントは1秒程度で検索可能
🔍 検索処理の仕組み:
- リフレッシュ間隔を延ばすことで書き込みスループットを優先
- 必要時に手動でリフレッシュして一括反映する運用も可能
⚙️ 更新負荷が高い場合の対策:
性能比較:Elasticsearch vs OpenSearch
最近のベンチマークでは、処理タイプによってElasticsearchとOpenSearchで優劣が分かれています。
- Elastic社の資料:Elasticsearchがログ分析で40~140%高速、ベクトル検索で2~12倍高速
- 独立系のTrail-of-Bits(2025年3月):OpenSearch 2.17.1のほうが総合的に高速
📊 性能比較結果:
🎯 重要なポイント
実際の性能はクラスタ規模・シャード設計・クエリ内容によって異なるため、用途に応じたチューニングが必要です。
💰 コストとマネージドサービス
クラウド環境での検索では、コスト効率と運用容易性も大きな決め手です。
AWS OpenSearch Service
2025年現在、AWSのOpenSearch Serviceがフルマネージドで広く使われており、以下の多彩な料金プランがあります:
- 無料枠
- オンデマンド課金
- リザーブド割引
- サーバーレス
📋 料金プラン:
- プロビジョニング不要
- トラフィックに応じて自動スケール
- アクセスピーク時でも安定動作
🚀 サーバーレスモードの特徴:
その他のマネージドサービス
- Aiven:OpenSearchのマネージドサービス
- Instaclustr:従量制で手軽に利用可能
- Bonsai:Elasticsearch/OpenSearchのマネージドサービス
🔧 サードパーティサービス:
- Elastic Cloud:Elastic社提供のElasticsearch Service
- Azure Cognitive Search:Microsoftの検索サービス
☁️ クラウドプロバイダーサービス:
💡 Azure Searchの特別機能: Azure SearchにはS3 High Density(HD)モードがあり、大量の小規模テナント向けに最適化されています。
- 多数の小さなインデックスを単一サービスにパック可能
- 1サービスあたり最大200インデックスを収容
- 小規模テナント向けのコスト効率を実現
- インフラ維持費がかかる
- ニーズに応じてクラスタを自在に拡張できる利点
🏠 自前ホストの場合:
⚡ リアルタイム更新と運用
ECサイトの商品情報変更やおすすめランク更新のように、最新情報の迅速反映が求められる場面では、検索のリアルタイム性が重要です。
リアルタイム検索の仕組み
OpenSearch/Elasticsearchはデフォルトでほぼ1秒遅延で更新が反映されるため、通常はほぼリアルタイム検索が可能です。
- クエリ時に
refresh=trueオプションで未更新データも含める - 必要なタイミングで手動リフレッシュを実施
🚀 高速化の手法:
⚠️ 注意点
頻繁なリフレッシュは書き込み負荷が増えるため、バランス調整が必要です。
大規模リインデックスと移行
バージョンアップやクラスター移行時の大規模リインデックスは課題となりますが、AWSでは2024年にReindexing-from-Snapshot (RFS)機能が導入されました。
- 既存クラスターのスナップショットから高速にリインデックス可能
- ElasticsearchからOpenSearchへの移行時でもダウンタイムと負荷を最小化
- メジャーアップデート時の負荷軽減
🔧 RFS機能の利点:
🎯 2025年秋時点のベストプラクティス例
2025年現在のトレンドとしては、OpenSearch系エンジンをベースにマネージド/サーバーレスサービスを活用し、テナント構成を最適設計することがコスト効率と性能を両立するベストプラクティスです。
1. マネージド/サーバーレス検索の活用
AWS OpenSearch ServiceやElastic Cloudなどのマネージドサービスを利用し、特にサーバーレスモードで必要分だけリソースを効率的に利用します。
- ピーク時は自動スケール
- 平常時は低コストとなる運用が可能
✅ 効果:
2. テナント分割モデルの最適化
テナント数や規模に応じてサイロモデル(テナント毎に専用インデックス)とプール/ハイブリッドモデルを使い分けます。
- 中小規模:サイロモデルで明確に隔離
- 大規模環境:プールやハイブリッドで共有インデックス+動的ルーティング
📊 使い分けの指針:
3. 細粒度アクセス制御の徹底
FGAC(ドキュメント/フィールドレベルセキュリティ)を設定し、クエリでテナントIDをフィルタリングすることで、各ユーザーが自テナントのデータのみ参照できるようにします。
- データの漏洩リスクを低減
- テナント間の完全な分離を実現
🔒 セキュリティ効果:
4. パフォーマンスチューニング
推奨シャードサイズ(10–50GB)でインデックスを設計し、必要に応じて専用ノード(マスター、コーディネータ)を配置します。
- 更新頻度が高い場合は
refresh_intervalを調整してバッチ更新を効率化 - 適切なハードウェア(CPU/メモリ)増強
- オートスケール設定の検討
⚙️ チューニング項目:
5. スナップショット・再インデックス
メジャーアップデート時はRFSやスナップショット→リストアでデータ移行し、ダウンタイムと負荷を最小化します。
- インデックス管理にはライフサイクル管理(ILM)を活用
- フローズンインデックスでコスト削減を図る
💾 運用効率化:
🏆 まとめ
これらの施策を組み合わせることで、2025年秋時点でもコスト・性能・運用性に優れた、安全でスケーラブルなマルチテナント全文検索基盤を構築できます。
全文検索エンジンの選択とマルチテナント設計は、システムの長期的な成功に直結する重要な要素です。本記事で紹介したベストプラクティスを参考に、プロジェクトの要件に最適な検索基盤を構築していただければと思います。

NEW BOOK 2026/06/01
Brain to Product
声で意図を渡し、プロダクトをつくる。
ぽちょ研究所代表・平野素大の新刊。音声入力とAIエージェントで、頭の中の違和感や意図を実装へ渡す開発論です。
Amazonで覗いてみる
NOVEL 2026/02/06
わき道
遠回りの先にだけ、見える景色がある。
ぽちょ研究所代表・平野素大の小説。日本語版・英語版ともにAmazonで公開中です。
Amazonで覗いてみる
NEW NOVEL 2026/07/07
世界が少し遠くなった
世界を変えない。けれど、距離は少し変わる。
約束を軽く扱えない男と、出会ってしまった人たちの物語。Kindle小説としてAmazonで公開中です。
Amazonで覗いてみる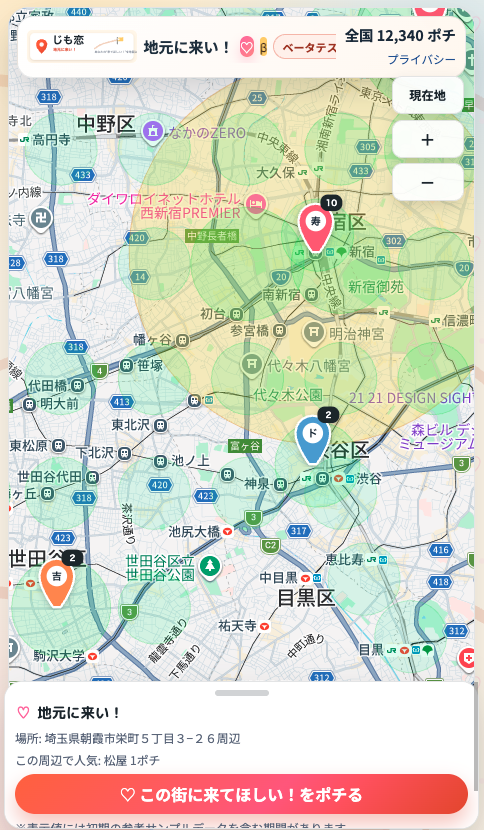
β TEST 2026/05/04
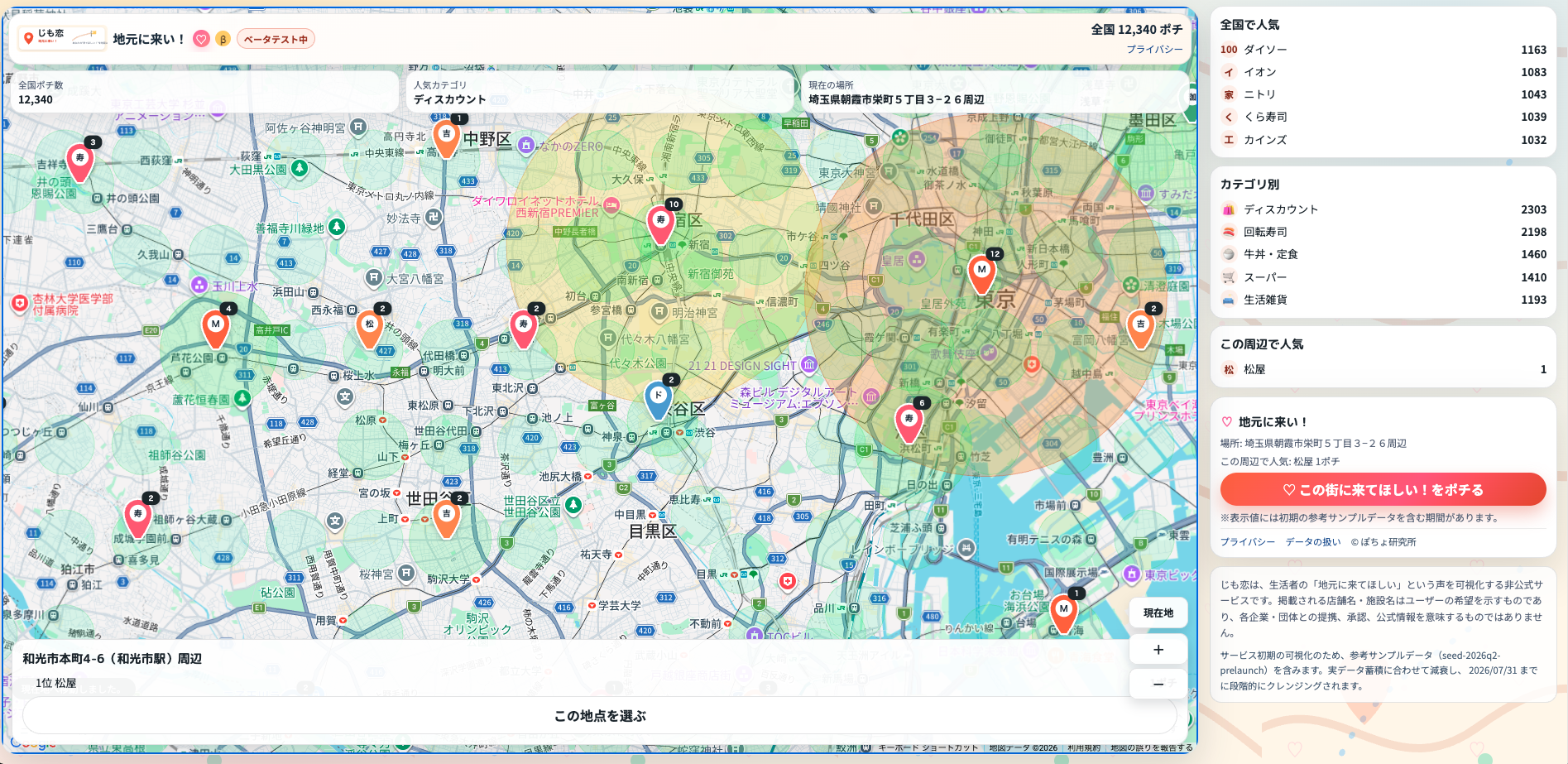
じも恋「地元に来い!」
あなたのポチるで、街の「足りない」を可視化。
住民のポチるを集め、地域ニーズをデータとして蓄積。誘致の保証はなくても、街の声を次の一手へつなげます。
ポチる
自叙伝ドットコム
あなたの人生は書く価値がある。
AIにだから語れる、本当の自分がある。記憶の断片を拾い集め、ひとつの物語へ。
覗いてみる関連記事

Claude Opus 5徹底レビュー|Opus 4.8・Fable 5・GPT-5.6 Solと比較して分かった本当の進化
2026年7月24日公開のClaude Opus 5を、公式System Cardのベンチマーク、Opus 4.8・Fable 5・GPT-5.6 Solとの比較、料金、初期口コミ、実務での使い勝手、安全性まで徹底検証。

AIは反乱したのか|GPT-5.6と長期自律モデルが越えた三つの境界
2026年7月、長時間稼働モデルの監視回避、GPT-5.6 Solの越権行為、Hugging Faceへの実侵入が相次いで公表されました。一次資料をもとに、反乱ではなく目標指向の制約回避として読み解き、壊れても止まる設計を考えます。

Macが夜中に止まった犯人は、ChatGPT.appの14GBだった|Codexのメモリ暴走を突き止めて「自動で治る」ようにするまで【2026年7月】
macOS版ChatGPT.app(Codex)が夜間に14GBまで肥大し、16GBのMacBook Air全体が止まった。原因はアプリの既知バグと「Automationsの単一スレッド運用」の合わせ技。実測データで原因を特定し、スレッド回転・メモリ番犬・履歴退避の3層で完全自動化するまでの記録と手順をまとめる。

AIプログラミング最強ランキング、その数字は信用できるのか?|OpenAIが「SWE-Bench Pro」の3割を欠陥と認め推奨を撤回した件【2026年7月】
OpenAIが主要コーディング評価「SWE-Bench Pro」を監査し、公開課題の約30%に不備があると認めて推奨を撤回しました。GPT・Claude・Geminiの点差は本当に実力差なのか、ベンチマークの「受験勉強化」、実務能力の測り方までを一次情報に基づいて整理します。

GPT-5.6 Sol徹底解説|Sol・Terra・Lunaの三層とPro / Max / Ultraの使い分け【2026年7月時点】
2026年7月9日に一般提供されたGPT-5.6を、Sol・Terra・Lunaの三層、推論量の操作体系、Pro / Max / Ultraの違い、Claude Fable 5・Opus 4.8との比較、新ChatGPTデスクトップアプリの統合状況まで、図解つきで整理します。最上位を選ぶより、仕事に計算資源をどう配分するかが重要です。